Since launching Synapse Pro to support nation-scale Matrix deployments, we’ve had a lot of questions asking how it differs from vanilla “community” AGPL Synapse.
We held back a bit on the details because Synapse Pro is evolving rapidly with optimisations for scalability and availability in many different areas, so we wanted to wait before publishing quantified comparisons.
However, the world doesn’t stand still, and we’re seeing some very high profile nation-scale Matrix projects planning to build out enormous multi-million user Matrix deployments using the community version of Synapse. Which, for the sake of a colourful analogy, is like trying to host the Olympics in your local gym.
Community Synapse is intended to let the Matrix community run their own small, medium and even large homeservers in the public Matrix network, and so help grow a big and vibrant open Matrix ecosystem and network. However it is not remotely designed or intended for use by commercial Matrix hosting providers to serve huge nation-scale deployments such as public healthcare insurance companies, and it will fail when used at this scale. Just as a suspension bridge has a weight limit and will collapse if you exceed it - the same goes for community Synapse.
Concretely: community Synapse provides scalability for larger traffic loads via worker processes written in Python. Each worker process uses at most 1 core of CPU (due to Python’s Global Interpreter Lock), and listens to all the activity happening on the server. For instance, on a server processing 40 events per second, each worker process typically uses 25% of its available CPU maintaining its caches and listening to messages, typing notifications, membership changes etc - all before it actually does any actual work. Here’s the CPU graph of a typical community Synapse worker participating in such a server, spending 25% of its time simply keeping up-to–date:
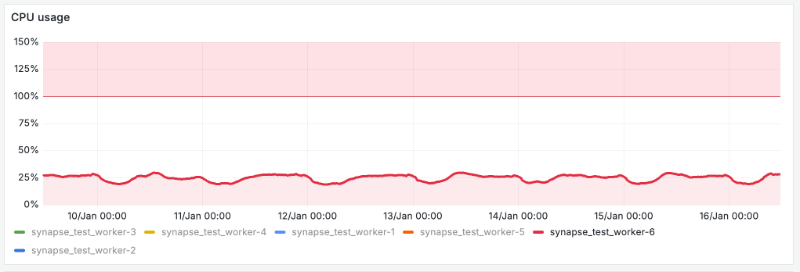
Now, this is fine for a reasonably large Matrix server - for instance 40 events/second is roughly what you might expect from a server with ~50K simultaneous users.
However, it should be obvious that if the traffic levels spiked higher by 3x to ~120 events/s - then 75% of the worker’s time would be spent simply listening to traffic, leaving only 25% available for doing work. At this point, the workers would obviously rapidly start running out of headroom to function, and the service will crash, no matter how many workers you add.
This is one of the key architectural issues of community Synapse that Synapse Pro addresses. It provides a Matrix homeserver implementation which benefits from Synapse’s maturity, while explicitly being designed to be resilient to traffic spikes and enormous user bases.
Synapse Pro does this by:
- Reimplementing Synapse’s worker processes in Rust, so that each can use as many CPU cores as the hardware has available - while also massively benefiting from the performance of Rust’s zero-cost abstractions and natively compiled code, relative to Python.
For instance, an idle Synapse Pro worker written in Rust uses less than 3% CPU to participate in the same server above - an almost 10x improvement in performance already. However, given Rust workers can now use all available CPU cores, you don’t need to run more than one per server - so on a typical large server with 64 cores, only 0.05% of the total CPU would actually be spent on participation overhead. This alone is a >500x scalability improvement over community Synapse, supporting millions of concurrent users, as needed for a nation-scale deployment. - Supporting elastic scaling. Synapse Pro’s workers are designed to be elastically added and removed without any server disruption (unlike community Synapse, which has to be restarted to pick up new workers). It lets Element Server Suite elastically scale worker resources via Kubernetes in order to handle traffic spikes and surges - and provides High Availability by swapping workers in and out in case of hardware failure.
- Sharing data between Rust workers. Community Synapse workers each maintain their own cache of recently accessed data, so as you scale by adding more workers (one per CPU core), the memory footprint steadily increases with redundant data. Synapse Pro workers, however, are built to use shared data caches, minimising RAM footprint and server costs, and enabling high-density Matrix hosting. Efficient memory structures in Rust also means that the worker’s memory footprint is already ~5x smaller than Python.
- Enabling other upcoming optimisations. For instance, worker scalability could be improved even more beyond the 500x improvement by only having workers listen to relevant traffic, rather than the firehose they currently consume - this, and other scalability work designed to benefit enormous server deployments, will land in Synapse Pro throughout 2025.
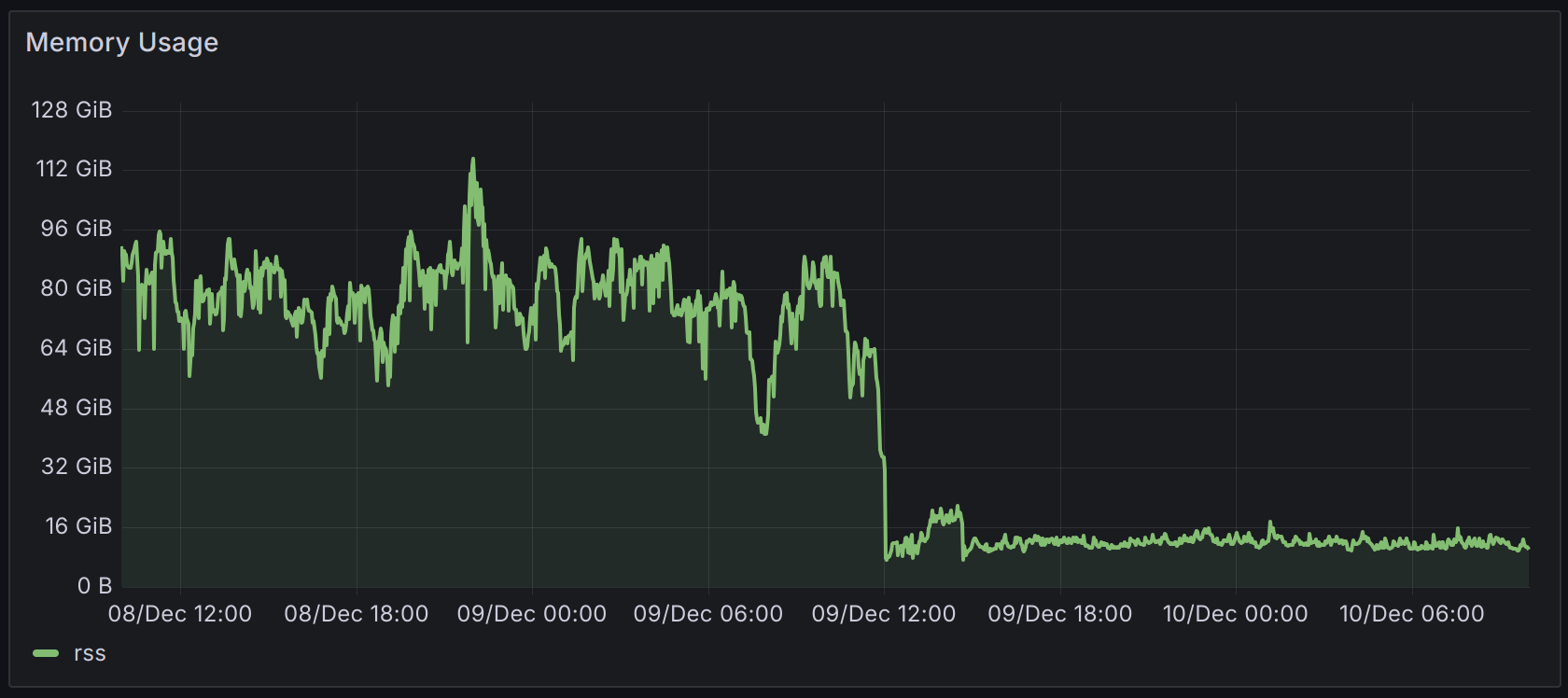
As an example, here’s the memory impact of the Federation Reader workers on Matrix.org being switched over from Synapse to Synapse Pro at the end of last year, in order to reduce hardware costs for The Matrix.org Foundation:
It’s worth reiterating that community Synapse continues to be Element’s primary focus, and new features, experimental implementations for Matrix Spec Changes, security work and general maintenance lands in community Synapse first to the benefit of the whole Matrix ecosystem - including general performance improvements.
So while Element is fully committed to community Synapse - and has made more than 90% of the contributions - we are specifically not developing it to support nation-scale deployments. Such huge deployments need a significantly different architecture, which is what Synapse Pro delivers and why features such as worker scalability - which is designed for enormous, commercial deployments - will only be available in Synapse Pro.
Governments and public sector organisations have a duty to ensure that the public money they spend on public code helps fund the underlying open source project. Nation-scale deployments need to ensure that development of the underlying Matrix protocol is well funded, rather than letting systems integrators free-ride on FOSS in order to maximise their margin while giving nothing back to the community.
Investing in a supported best practice distribution designed for nation-scale usage, such as Element Server Suite using Synapse Pro, guarantees huge deployments benefit automatically from the highest levels of security, maintenance and performance plus full support by the people who designed and built it - and ensures the health of the underlying open source project.
EDIT - Jan 20th 2025: There's been some concern over what this means for performance work in community Synapse, so to clarify:
- Core work in Synapse will continue to be open source, just as it always has been.
- Many aspects in smaller Synapse instances today are typically NOT related to the question if workers are primarily written in Rust or Python (in fact, smaller instances often don't use workers at all!)
- Instead, within community Synapse, Element intends to improve algorithmic complexity of state resolution and state storage; to increase database schema efficiency; to introduce shared retry hints for federation; to further develop faster room joins; to develop alternatives to full-mesh federation; etc.
- We will conduct other core work in open source Synapse, with development hopefully driven by funding derived from Synapse Pro.
- Open source Synapse remains the primary project, and this code will land there first.
- The features landing in Synapse Pro are primarily those related to removing bottlenecks on scaling beyond a given size (i.e. giving workers more CPU headroom), and high density multi-tenancy deployments that would support thousands of tiny instances (say, a single solution that serves an entire nation’s independent pharmacies).
- TL;DR: Synapse Pro is aimed at eliminating the bottlenecks which impact massive deployments... while generating funding to improve Synapse for everyone.


